
海量信息在AI面前不值一提,以后藏私密文件可费劲了。
有个老伙伴离职,把自己电脑格式化完走人了(ssd固态硬盘)。领导不爽,问问能恢复多少文档。
雇主有需求,咱就要配合。找个盗版恢复软件扫了一遍,还真的恢复了一些文件,可惜没有文件名和路径了(只有软件给的序号)。
面对老伙伴千百个文件,有的能打开,有的打不开,头痛不已。一个一个看,看看里面什么东西?咱也没挣那份钱呀,还是把这活转成技术问题好了,好歹还能练练手。
于是乎,在朋友的介绍下,选了一个可以上传文档的AI模型——讯飞星火知识库。
不是说别的不行,RPA机器人模拟操作一个个上传到网页上的gpt也是可以干的,只是这没啥含量,而且速度堪忧。
借这个看看学学API怎么玩,更有意思。于是控制台-讯飞开放平台看着这个文档,借助gpt学python语法,好歹·把第一个demo里的东西搞明白了。
后续上手干。
遍历指定文件夹
获取文件名,文件路径
文件上传给星火知识库
发起文档总结概要
获取文档总结
把文件名,文件路径,文档总结写入结果表。
很快就知道这些文档大概是什么内容了。
如果根据总结再调用个起名字的聊天AI,大差不差也能起个相当靠谱的文件名了。(这步没干)
思路弄完了,单文件总结很快就弄出来。
用的影刀,省的配环境。
功能函数如下(鉴权和参数部分就不发了)
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
# -*- coding:utf-8 -*-
import hashlib
import base64
import hmac
import time
import random
from urllib.parse import urlencode
import json
import requests
from requests_toolbelt.multipart.encoder import MultipartEncoder
from .import xunfei_canshu
def main(args):
pass
# docupload("ds")
# doclist("ads")
def docupload(file_name, file_path, needSummary):
request_url = "https://chatdoc.xfyun.cn/openapi/v1/file/upload"
# 提交本地文件
body = {
"url": "",
#"fileName": "背影.txt",
"fileName": file_name,
"fileType": "wiki",
#"needSummary": False, 上传时是否总结有时是管用的(有时无效,可能需要等待),false时需要自己总结
"needSummary": needSummary,
"stepByStep": False,
"callbackUrl": "your_callbackUrl",
}
# files = {'file': open('背影.txt', 'rb')}
# files = {'file': open(r'D:\work\xunfei\背影.txt', 'rb')}
files = {'file': open(file_path, 'rb')}
APPId, APISecret, headers = xunfei_canshu.main("test")
response = requests.post(request_url, files=files, data=body, headers=headers)
# print("请求头", response.request.headers, type(response.request.headers))
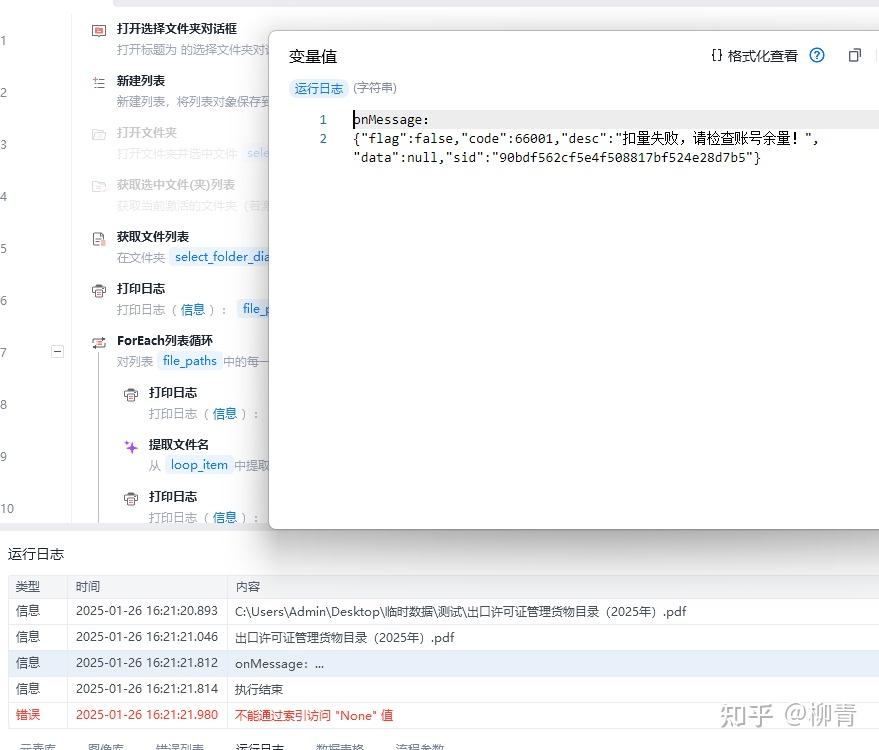
print('onMessage:\n' + response.text)
try:
response_json = response.json()
# 获取 fileId
file_id = response_json['data']['fileId']
print("File ID:", file_id)
return (file_id)
except ValueError as e:
print("Error parsing JSON:", e)
except KeyError as e:
print("Key not found in JSON response:", e)
def doclist(args):
request_url = "https://chatdoc.xfyun.cn/openapi/v1/file/list"
body = {
#"fileName": "背影", #模糊查询
#"extName": "TXT",
#"currentPage": 1,
#"pageSize": 10
}
APPId, APISecret, headers = xunfei_canshu.main("test")
response = requests.post(request_url, json=body, headers=headers)
# print("请求头", response.request.headers, type(response.request.headers))
print('onMessage:\n' + response.text)
files_info = []
try:
data = response.json()
for row in data['data']['rows']:
files_info.append({'fileId': row['fileId'], 'fileName': row['fileName']})
print(files_info)
return files_info
except ValueError as e:
print("Error parsing JSON:", e)
except KeyError as e:
print("Key not found in JSON response:", e)
#def docdelet(*args): #*args允许你传递任意数量的文档ID,比如docdelet("docId1", "docId2", "docId3")
def docdelet(args):
# ******************11、文档删除*******************************
request_url = "https://chatdoc.xfyun.cn/openapi/v1/file/del"
body = {
"fileIds": [
# list(args) #请填写文档id
args
]
}
# print(headers)
APPId, APISecret, headers = xunfei_canshu.main("test")
response = requests.post(request_url, data=body, headers=headers)
# print("请求头", response.request.headers, type(response.request.headers))
# print('onMessage:\n' + response.text)
try:
response_data = response.json()
return response_data.get("desc", [])
except ValueError as e:
print("Error parsing JSON:", e)
except KeyError as e:
print("Key not found in JSON response:", e)
# 文档删除完成
# ****************删除全部知识文档****************
def del_alldoc():
print("删除全部文档")
data = doclist("ads")
# 使用列表推导式提取所有的 fileId 值
file_ids = [item['fileId'] for item in data]
#print (file_ids)
docdelet(file_ids)
# ******************4、文档状态查询*******************************
def zhuangtai_doc(args):
request_url = "https://chatdoc.xfyun.cn/openapi/v1/file/status"
APPId, APISecret, headers = xunfei_canshu.main("test")
body = {
"fileIds": [
args #请填写文档id列表
]
}
response = requests.post(request_url, data=body, headers=headers)
# print("请求头", response.request.headers, type(response.request.headers))
#print('onMessage:\n' + response.text)
try:
response_data = response.json()
#args为多个时id时,data是列表,要用列表的方式
data = response_data.get("data", [])
file_status_list = [item["fileStatus"] for item in data]
file_status = file_status_list[0]
#print(file_status_list,file_status)
# 返回列表如['vectored', 'vectored']
return file_status
except ValueError as e:
print("Error parsing JSON:", e)
except KeyError as e:
print("Key not found in JSON response:", e)
# 文档状态查询完成
# ******************8、文档总结发起,只支持单个的文档*******************************
def summary_doc(args):
request_url = "https://chatdoc.xfyun.cn/openapi/v1/file/summary/start"
APPId, APISecret, headers = xunfei_canshu.main("test")
body = {
"fileId": args #请填写文档id,不支持列表
}
# # print(headers)
response = requests.post(request_url, data=body, headers=headers)
# print("请求头", response.request.headers, type(response.request.headers))
print('发起总结返回值:\n' + response.text)
if response.status_code == 200:
try:
response_data = response.json()
return response_data.get("code", [])
except ValueError as e:
# 如果响应内容不是有效的JSON格式,捕获异常并打印错误信息
print('Error parsing JSON:', e)
else:
# 如果响应状态码不是200,打印错误信息
print('Request failed with status code:', response.status_code)
# 文档总结发起完成
# ******************7、文档总结查询*******************************
def get_summary(args):
request_url = "https://chatdoc.xfyun.cn/openapi/v1/file/summary/query"
APPId, APISecret, headers = xunfei_canshu.main("test")
body = {
"fileId": args #请填写文档id,单个字符串类型
}
# # print(headers)
response = requests.post(request_url, data=body, headers=headers)
# print("请求头", response.request.headers, type(response.request.headers))
print('获取总结返回值:\n' + response.text)
if response.status_code == 200:
try:
response_data = response.json()
summary = response_data["data"].get("summary")
summary_status = response_data["data"].get("summaryStatus")
return summary_status, summary #return response_data["data"].get("summary")
except ValueError as e:
# 如果响应内容不是有效的JSON格式,捕获异常并打印错误信息
print('Error parsing JSON:', e)
else:
# 如果响应状态码不是200,打印错误信息
print('Request failed with status code:', response.status_code)
# 文档总结发起完成
# 文档总结查询完成
# ******************3、文档向量化 仅对拆分的文档有效,不能快速向量化,鸡肋*******************************
def embedding(args):
request_url = "https://chatdoc.xfyun.cn/openapi/v1/file/embedding"
APPId, APISecret, headers = xunfei_canshu.main("test")
body = {
"fileIds": [
args #请填写文档id
]
}
response = requests.post(request_url, data=body, headers=headers)
# print("请求头", response.request.headers, type(response.request.headers))
print('向量化结果:\n' + response.text)
try:
response_data = response.json()
return response_data.get("code", [])
except ValueError as e:
print("Error parsing JSON:", e)
except KeyError as e:
print("Key not found in JSON response:", e)
# 文档向量化完成小结:
1,这个东西限使用量,免费的不够用。找找有没有类似的api可以免费干活。
2,文档概要总结,要等待,时间不确定。测试发现这个api,文档上传后,就只是上传,他还有被向量化,等待总结完成。(api原来并不是干这个用的,时效性方面差点意思,所以可以理解)
正常的流程是用回调接收,上传的文档什么时候总结好了,系统会发送回来告诉你,等一切都ok了你再用。
我自己做的流程不是这样,希望上传后,发起总结,拿到结果后,把文档删掉。所以总是拿不到结果。
3,总结的效果还是很好的,doc,pdf,txt都能看。要是能总结excel的就更好了。
4,有了AI辅助,新手外行搞个小开发小功能的东西也不难了。
杂念:
细思极恐。
以前种个木马啥的我并不担心,因为电脑里没啥值得被偷的东西。把我硬盘里的东西都拿走也无所谓,因为从万千文件中找到一点儿儿有价值的东西,黑客所需要的时间成本比他获得的要高的多。
现在可就不一样了,借助ai,你这电脑里哪些文档,文档写的啥,哪些可能有价值,人家随随便便看明白,时间成本大大降低了。
他们可以卖你的客户,卖你写的报告,卖你的照片,分析你存的视频到底都是关于什么的(自动提取关键帧,给出描述总结),总之搞明白你电脑里到底有什么,你到底是干什么的都很简单。
以后,还是自己的电脑,AI比主人都了解哪些文件放在哪里。
新环形镜下,靠海量信息去保护关键信息的方式要失效了。管网的管电脑的,人家又多了一个利器,打工人的摸鱼空间又少了。
应对之道,自己琢磨吧。
大聪明::
肯定有小伙伴会聪明的告诉你,重要文件放到加密盘。
加密确实容易,但是用起来累,麻烦别人的时候,同时便麻烦了自己。
