
学而时习之,文本处理时发现个问题,把采集来的html代码用正则匹配去掉标签后会留下各式各样空行换行。
去网上找解决方案,看到这位大神写的还是很靠谱的。遇到的问题基本都能解决。
正则表达式去空行,废话不多说,把人家的代码搬过来,留着用是个好习惯。
一个空行,可能包括,换行符, ,空格。对字符串进行处理时,难免会遇到对空行进行处理。
1,替换空行,空行可包括空格, ,\t,\f,\n
$s= preg_replace('/(^(\s| )*$)/m', '',$s);
2,替换空行,只包括换行符
$s= preg_replace('/(($\n\r*$)|(^\n\r*^))+/m', '',$s)
3,替换空行,并将非空行的开头和结尾的空格去掉
$s= preg_replace('/^( |\s)*|( |\s)*$/m', '',$s);
4,不匹配空行,直接不匹配空行,挺难的。其实不匹配空行,就是匹配非空行
preg_match_all('/\S+/m',$s,$match);
5,多行匹配实例
$s= "
test:
11111
22222
33333333333333333333
44444444444444444444
";
$s= preg_replace('/(^(\s| )*$)/m', '<br>',$s);
$pa= "/test:(((\s)*[^<]*)*)/i";
preg_match($pa,$s,$m);
echo$m[1];
匹配test行到下面多空行之间的内空,也是11111,22222
6,常用匹配模式
i 模式中的字符将同时匹配大小写字母
m 字符串视为多行
s 将字符串视为单行,换行符作为普通字符
x 将模式中的空白忽略
e preg_replace() 函数在替换字符串中对逆向引用作正常的替换,将其作为 PHP 代码求值,并用其结果来替换所搜索的字符串。
A 强制仅从目标字符串的开头开始匹配
D 模式中的 $ 元字符仅匹配目标字符串的结尾
U 匹配最近的字符串
u 模式字符串被当成 UTF-8正则表达式去空行,测试效果如下
测试工具https://c.runoob.com/front-end/854 注^前面加个空格或者/才能达到预期效果,这可能是这个工具的小bug。
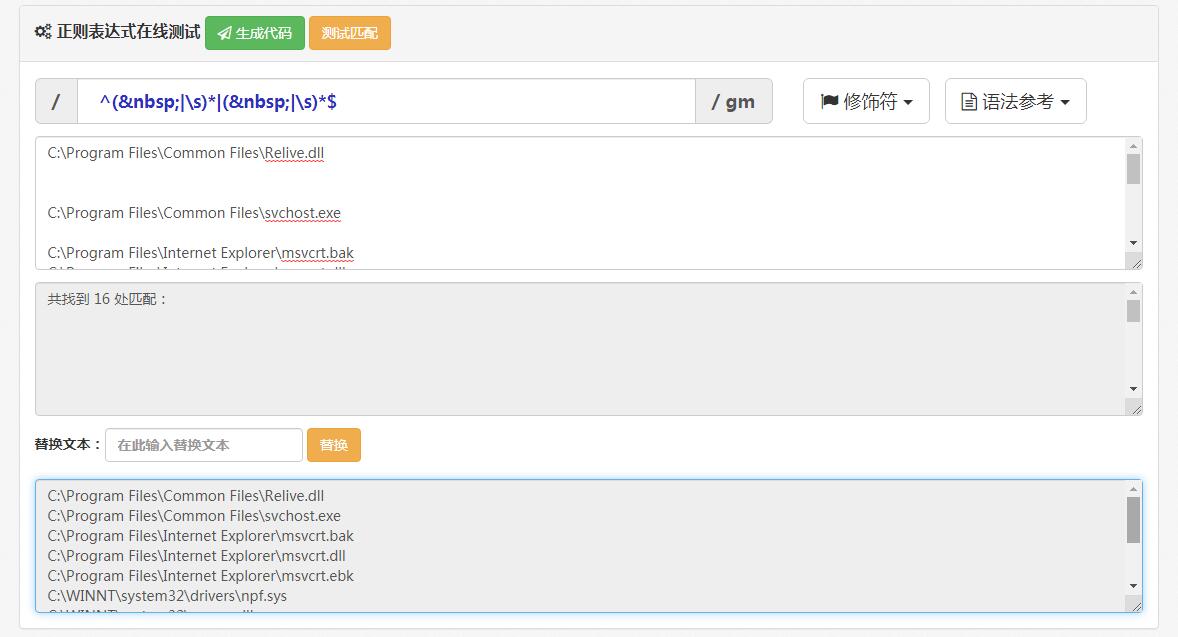
正则表达式测试
