
如题,有个表想要多条记录合并到一个单个字段并且存成一条。
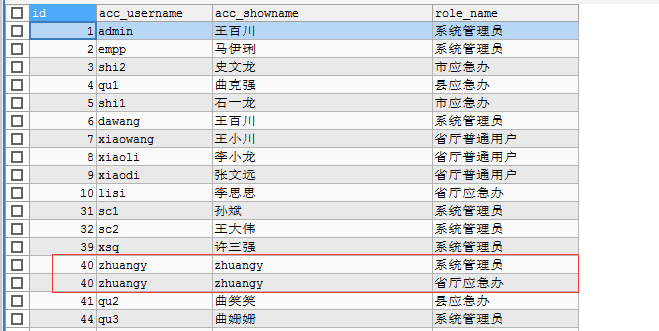
想要的效果

mysql比较简单,group_concat函数就能搞定。
SELECT acc.id,acc.acc_username,acc.acc_showname,GROUP_CONCAT(T_PM_ROLE.role_name) FROM T_ACCOUNT acc,T_ACCOUNT_R_ROLE accRole ,T_PM_ROLE WHERE acc.is_active =1 AND (accRole.is_active =1 AND acc.id = accRole.acc_id) AND accRole.role_id = T_PM_ROLE.id GROUP BY acc_id
参考:http://www.cnblogs.com/wangtao_20/archive/2011/02/23/1961860.html
https://www.2cto.com/database/201302/188404.html
但是呢,咱用的mssql,这就坑爹了,没有这个函数。度娘一看
要参考
https://cloud.tencent.com/developer/ask/57675
https://jingyan.baidu.com/article/e3c78d641d275c7c4c85f5b3.html
主要的两个用到了STUFF用法和for xml path
SQL 中STUFF用法
1、作用
删除指定长度的字符,并在指定的起点处插入另一组字符。
2、语法
1 | STUFF ( character_expression , start , length ,character_expression ) |
3、示例
以下示例在第一个字符串 abcdef 中删除从第 2 个位置(字符 b)开始的三个字符,然后在删除的起始位置插入第二个字符串,从而创建并返回一个字符串
1 2 | SELECT STUFF('abcdef', 2, 3, 'ijklmn')GO |
下面是结果集
aijklmnef
4、参数
character_expression
一个字符数据表达式。character_expression 可以是常量、变量,也可以是字符列或二进制数据列。
start
一个整数值,指定删除和插入的开始位置。如果 start 或 length 为负,则返回空字符串。如果 start 比第一个 character_expression长,则返回空字符串。start 可以是 bigint 类型。
length
一个整数,指定要删除的字符数。如果 length 比第一个 character_expression长,则最多删除到最后一个 character_expression 中的最后一个字符。length 可以是 bigint 类型。
5、返回类型
如果 character_expression 是受支持的字符数据类型,则返回字符数据。如果 character_expression 是一个受支持的 binary 数据类型,则返回二进制数据。
6、备注
如果结果值大于返回类型支持的最大值,则产生错误。
这个STUFF看着简单。
再看看
mssql for xml path使用
参考:https://my.oschina.net/u/4334671/blog/3659582
准备工作:
| CREATE TABLE [dbo].[Students]( [id] [int] IDENTITY(1,1) NOT NULL, [names] [varchar](50) NULL, [hobby] [varchar](50) NULL )
insert into students values('张三','书法'),('张三','篮球'),('张三','台球'),('李四','书法'),('李四','唱歌'),('李四','足球'),('李四','乒乓球')
|
for xml path
把查询结果用xml表现出来。
1 正常的查询:
select * from Students
结果是:
id names hobby
----------- --------------------------------------------------
1 张三 书法
2 张三 篮球
3 张三 台球
4 李四 书法
5 李四 唱歌
6 李四 足球
7 李四 乒乓球
返回的是一个数据表格(多条)。
2 用xml表现
select * from Students for xml path
结果是:
XML_F52E2B61-18A1-11d1-B105-00805F49916B
------------------------------------------------------------------------------------
<row><id>1</id><names>张三</names><hobby>书法</hobby></row><row><id>2</id><names>张三</names><hobby>篮球</hobby></row
><row><id>3</id><names>张三</names><hobby>台球</hobby></row><row><id>4</id><names>李四</names><hobby>书法</hobby></row>
<row><id>5</id><names>李四</names><hob
也是一个数据表格(单条)
把查询结果做为xml数据格式返回了一行数据。
3 通过使用path()参数,可改变列节点:
select * from Students for xml path('')
结果:
XML_F52E2B61-18A1-11d1-B105-00805F49916B
-----------------------------------------------------------------------------------
<id>1</id><names>张三</names><hobby>书法</hobby><id>2</id><names>张三</names><hobby>篮球</hobby>
<id>3</id><names>张三</names><hobby>台球</hobby><id>4</id><names>李四</names><hobby>书法</hobby>
<id>5</id><names>李四</names><hobby>唱歌</hobby><id>6</id><names>李四</names><hobby>足球
使用path(‘’)空参数,去掉了row节点,直接显示的是两个属性字段。
4 自定义节点
select * from Students for xml path('selfNode')
结果如下:
XML_F52E2B61-18A1-11d1-B105-00805F49916B
--------------------------------------------------------------------------------------------
<selfNode><id>1</id><names>张三</names><hobby>书法</hobby></selfNode>
<selfNode><id>2</id><names>张三</names><hobby>篮球</hobby></selfNode>
<selfNode><id>3</id><names>张三</names><hobby>台球</hobby></selfNode>
<selfNode><id>4</id><names>李四</names><hobby>书法</hobby></selfNode>
总的来说,for xml path返回的是一条数据(一个xml字串)。所以,这个可以作为查询中的一列。如下:
select distinct aaa.names,hobby=(
SELECT hobby+',' FROM students
WHERE names=aaa.names
FOR XML PATH('')
)
from students aaa
结果如下:
names hobby
--------------------------------------------------
李四 书法,唱歌,足球,乒乓球,
张三 书法,篮球,台球,
从students表中查询names,且各自的hobby,hobby是多条记录,通过xml 整合到一条记录,并使用逗点分隔。
上面的语句中有一句:where names=aaa.names,因为for xml path返回的是一条数据字串,不能进行查询条件的关联,即不能做为数据表与其它表进行关联。
它只返回一行一列,且for xml path都整合到一字符串中而没有其它字段,所以不能与其它表进行联合查询。但可以在for xml之前进行联合查询,如下:
select distinct aaa.names,hobby=(
select hobby+',' FROM students
where names=aaa.names
for xml path('')
) from students aaa
for xml path部分的结果做为一个字段显示,而粗体部分表示把每个names中的hobby字段通过逗号连成一个字段,如下:
names hobby
--------------------------------------------------
李四 书法,唱歌,足球,乒乓球,
张三 书法,篮球,台球,
未使用distinct,结果如下:
names hobby
--------------------------------------------------
张三 书法,篮球,台球,
张三 书法,篮球,台球,
张三 书法,篮球,台球,
李四 书法,唱歌,足球,乒乓球,
李四 书法,唱歌,足球,乒乓球,
李四 书法,唱歌,足球,乒乓球,
李四 书法,唱歌,足球,乒乓球,
把重复的去掉,可通过group或distinct去掉
另外:对于可容忍的脏读而不死锁的with onlock在mssql中可在表后边使用with(nolock)脏读;今天查了一下,对于mysql来说,不需要使用with nolock,会自动使用nolock. 。这个我自己未做过测试,大概只是了解一下。
补充说明,hobby+','什么意思
这就是简单字符串合并语法,hobby的内容后面加个逗号而已。
如果只简单查询SELECT hobby+',' FROM students WHERE names=aaa.names不带for xml path,那么很简单,就是返回一个字段名为“空”的多行数据而已。
字段名为“空”才是奥妙所在,这个加上for xml path以后返回的xml就可以把字段名也去除掉。
<selfNode><hobby>书法</hobby></selfNode><selfNode><hobby>篮球</hobby></selfNode>
selfNode已经知道如何设成空变没了,字段名也没了,在拿逗号连接。终于就实现了所谓的合并。
不信改成 SELECT hobby+',' as lequ试试,<lequ>书法</lequ>讨厌的字段名又回来了。
后记:自己练手写了一个,还是很好用的。
select tb2.PurchaseOrderNo, tb2.ItemNo, tb2.Qty, tb4.ENGItemName, tb4.CHNItemName, tb4.SupplierShortName, tb4.Date, tb4.price, tb5.beizhu from (select PurchaseOrderNo, ItemNo, sum(QTY) as Qty from stock Where ItemNo='808171' group by PurchaseOrderNo, ItemNo having sum(QTY)<>0) as tb2 LEFT JOIN
(select * from(select PurchaseOrderNo, ItemNo, ENGItemName, CHNItemName, SupplierShortName, Date, price, row_number() over(partition by PurchaseOrderNo, ItemNo order by PurchaseOrderNo) as Qid from stock where ItemNo='808171' and stock.SourceType = '入库') tb3 where Qid = 1) tb4 on tb2.ItemNo = tb4.ItemNo and tb2.PurchaseOrderNo = tb4.PurchaseOrderNo LEFT JOIN
(select distinct tb1.PurchaseOrderNo, tb1.ItemNo, (select (cast(price as varchar) + '^|^' + AMemo + ';;') from stock where stock.PurchaseOrderNo = tb1.PurchaseOrderNo and stock.ItemNo = tb1.ItemNo and stock.SourceType = '入库' for xml path('')) as beizhu from stock tb1 where tb1.ItemNo = '808171') tb5 on tb2.ItemNo = tb5.ItemNo and tb2.PurchaseOrderNo = tb5.PurchaseOrderNo